5.3 KiB
TDT 4310 - Intelligent Text Analysis Project
Sorting japanese sentences by linguistic complexity
Overview
- Introduction and motivation
- Background
- Datasets
- Methodology
- Evaluation
- Conclusion, and further work
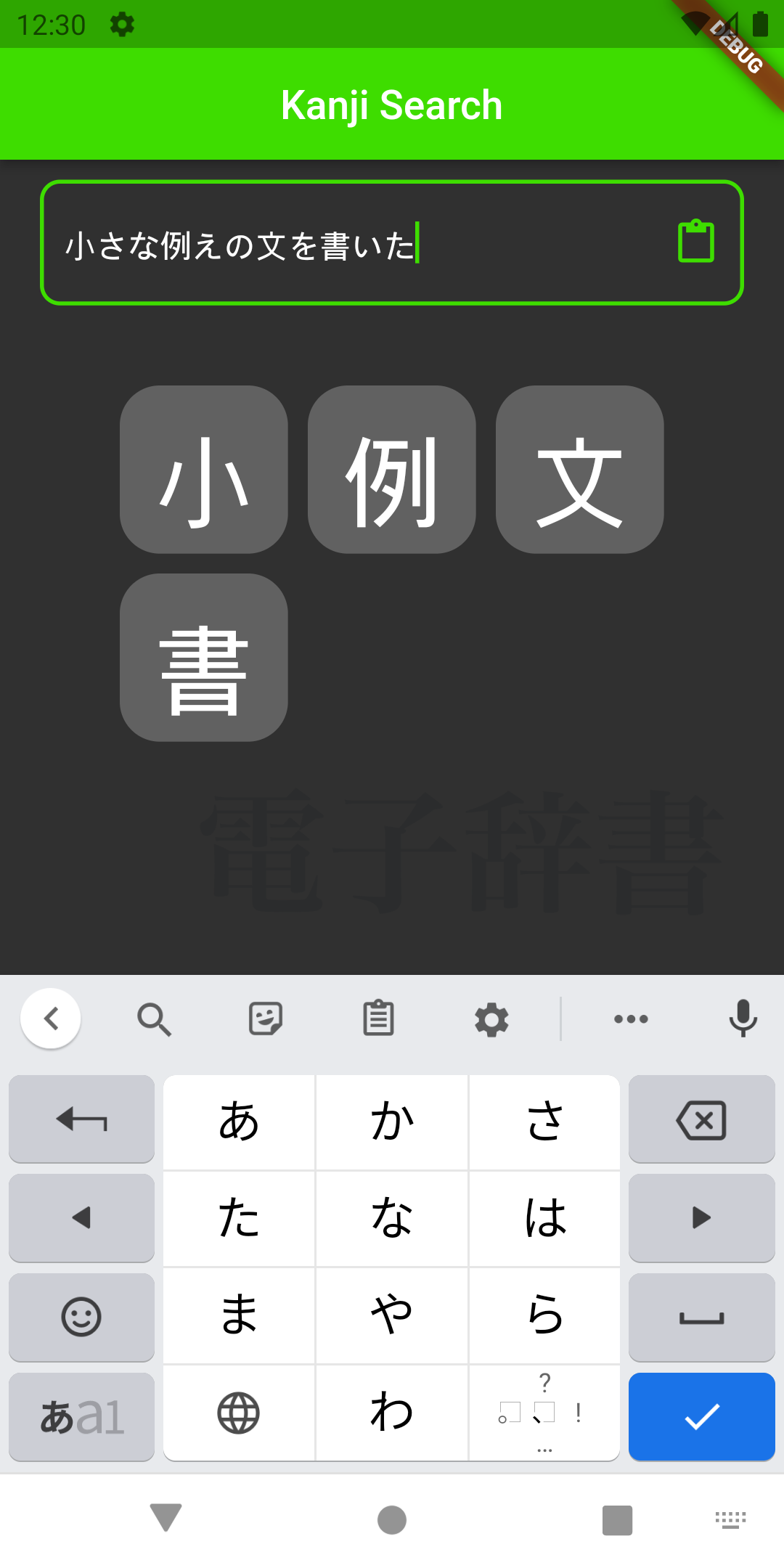

Motivation
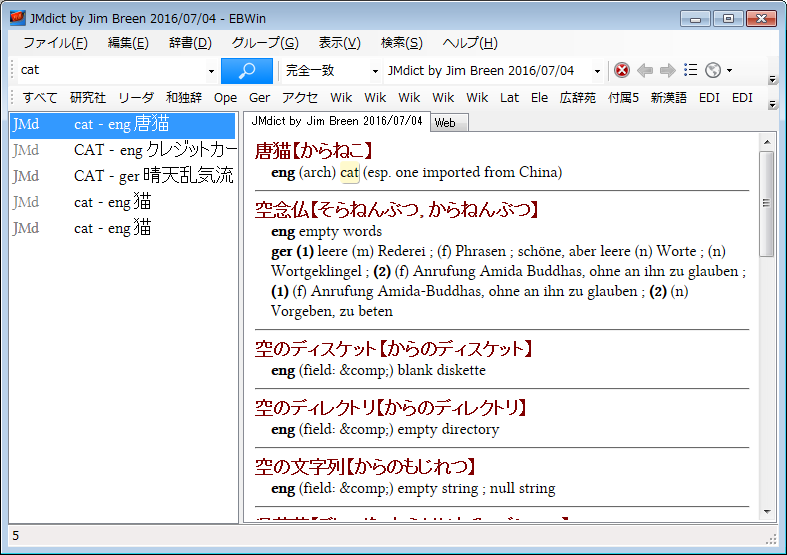
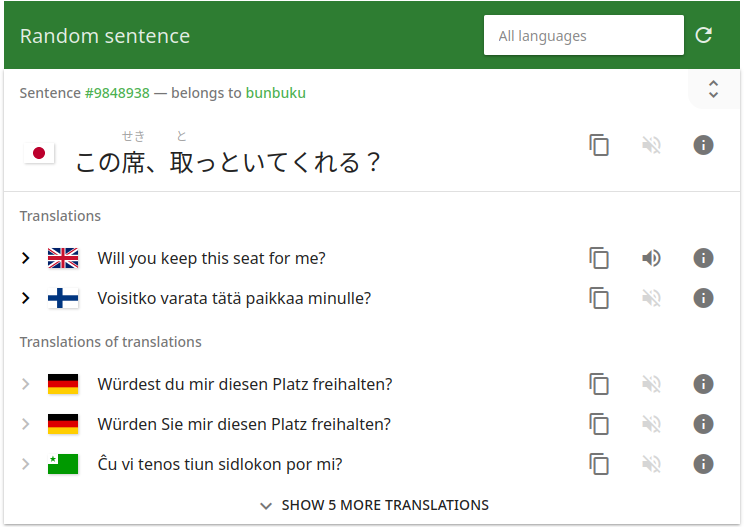
| JMDict | Tatoeba / Tanaka corpus | NHK Easy News | MeCab |
|---|---|---|---|
| Open source dictionary | Multilingual sentence pairs | Easy-to-read news articles | POS and morphological analyzer |
 |
 |
 |
Datasets
TF-IDF
Extract the most meaningful words of a document
Sense disambiguation
Pinpoint which sense of the word is used, based on surrounding context and grammar.
BackgroundJapanese
Three writing systems
| hiragana | katakana | kanji |
|---|---|---|
 |
 |
 |
10 ページ の 5 行目 をみなさい
Let's start from (the) fifth line on page 10
Multiple readings per kanji
形 - katachi, kata, gyou, kei
Furigana
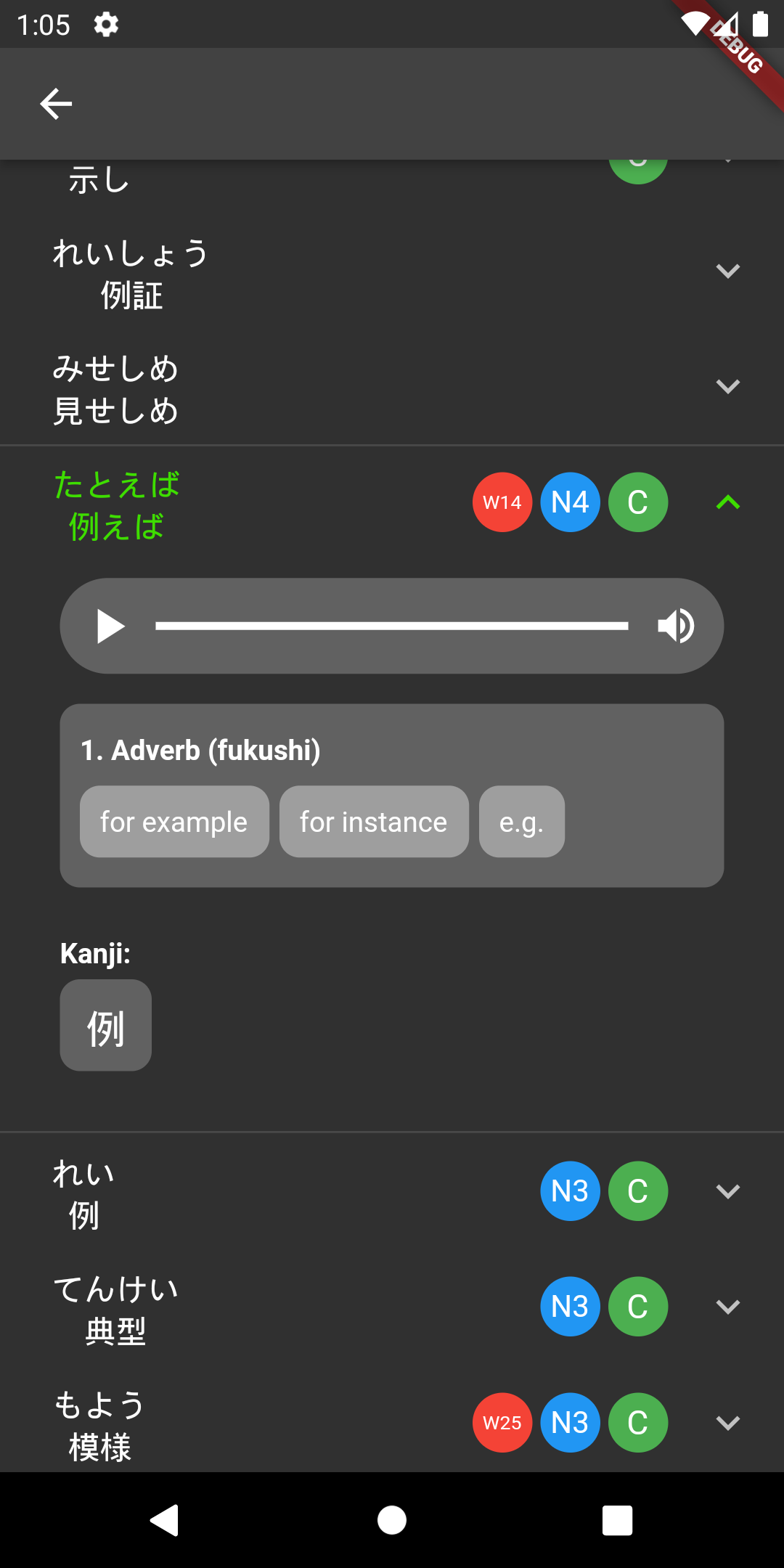
振 仮 名Data ingestion, preprocessing and disambiguation
Tanaka Corpus
信用█為る(する){して}█と█彼(かれ)[01]█は|1█言う{言った}
NHK News Articles
Scrape -> Extract text -> MeCab + Furigana -> Try disambiguating with POS
MethodologyNote:
Disambiguation here, is not necissarily sense ambiguation, but rather disambiguating the dictionary entry.
Could exploit the english translation to disambiguate all the way down to the word senses.
TF-IDF?
\text{TF-IDF} = \frac{\text{Amount of term in doc}}{\text{Amount of terms in doc}} \cdot log \frac{\text{Amount of docs}}{1 + \text{ Amount of docs containing term}}
\text{TF-DF} = \frac{AVG(\text{Amount of term in doc})}{\text{Amount of terms in doc}} \cdot \frac{\text{ Amount of docs containing term}}{\text{Amount of docs}}
Note:
TF-IDF is usually used for finding out how meaningful a word is to a document. Here, we want to do the opposite. The value should have a higher score, if it is more common across several documents.
Word difficulty
| Commonness | Dialects | Kanji | Katakana | NHK rating |
|---|---|---|---|---|
| 25% | 10 % | 25% | 15% | 25% |
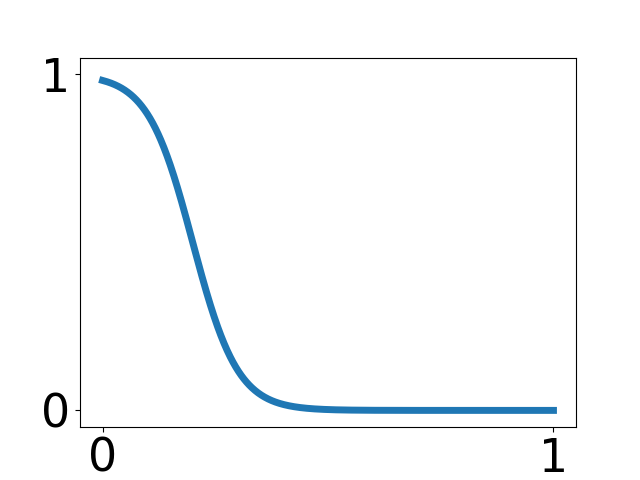 |
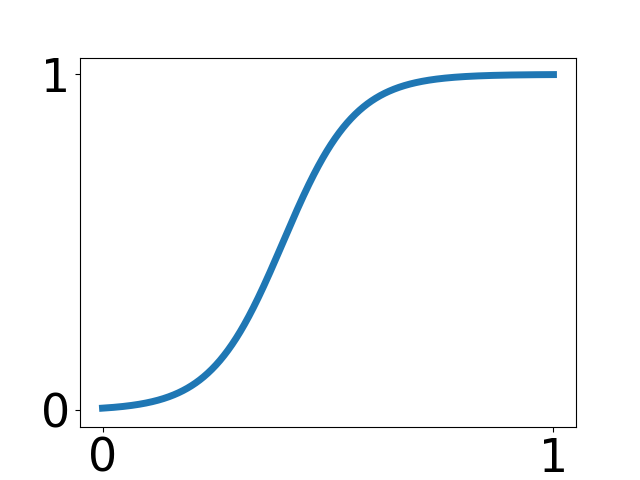 |
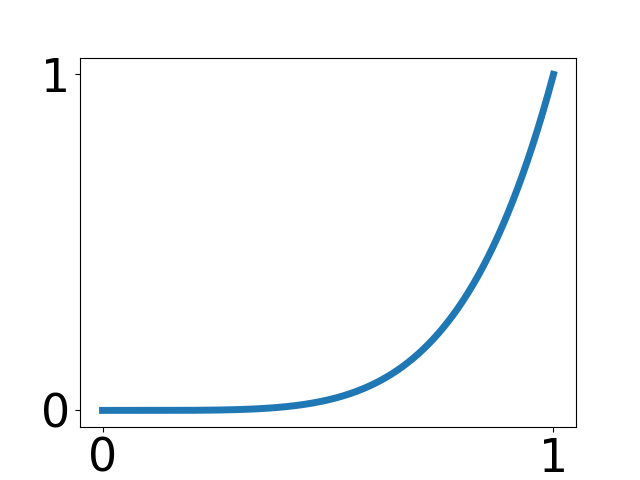 |
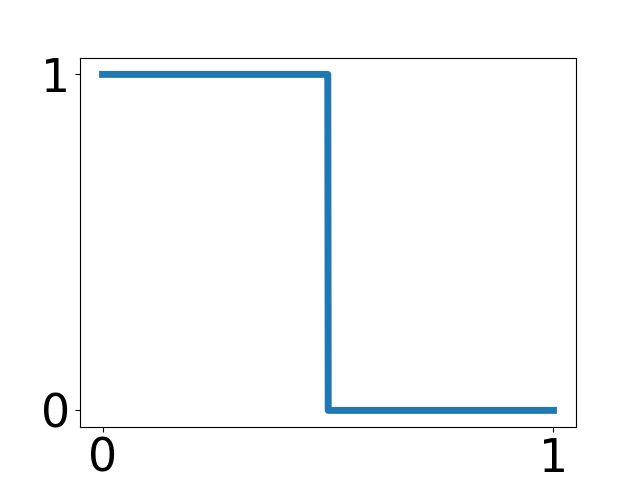 |
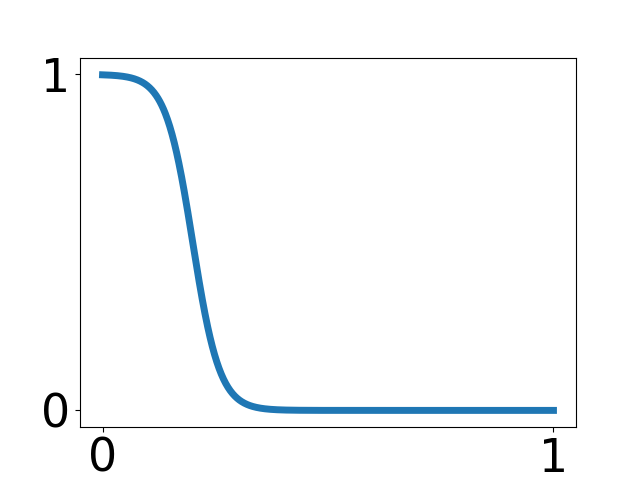 |
Sentence difficulty
| Word difficulty sum | Hardest word | Sentence Length |
|---|---|---|
| 50% | 20 % | 30% |
 |
 |

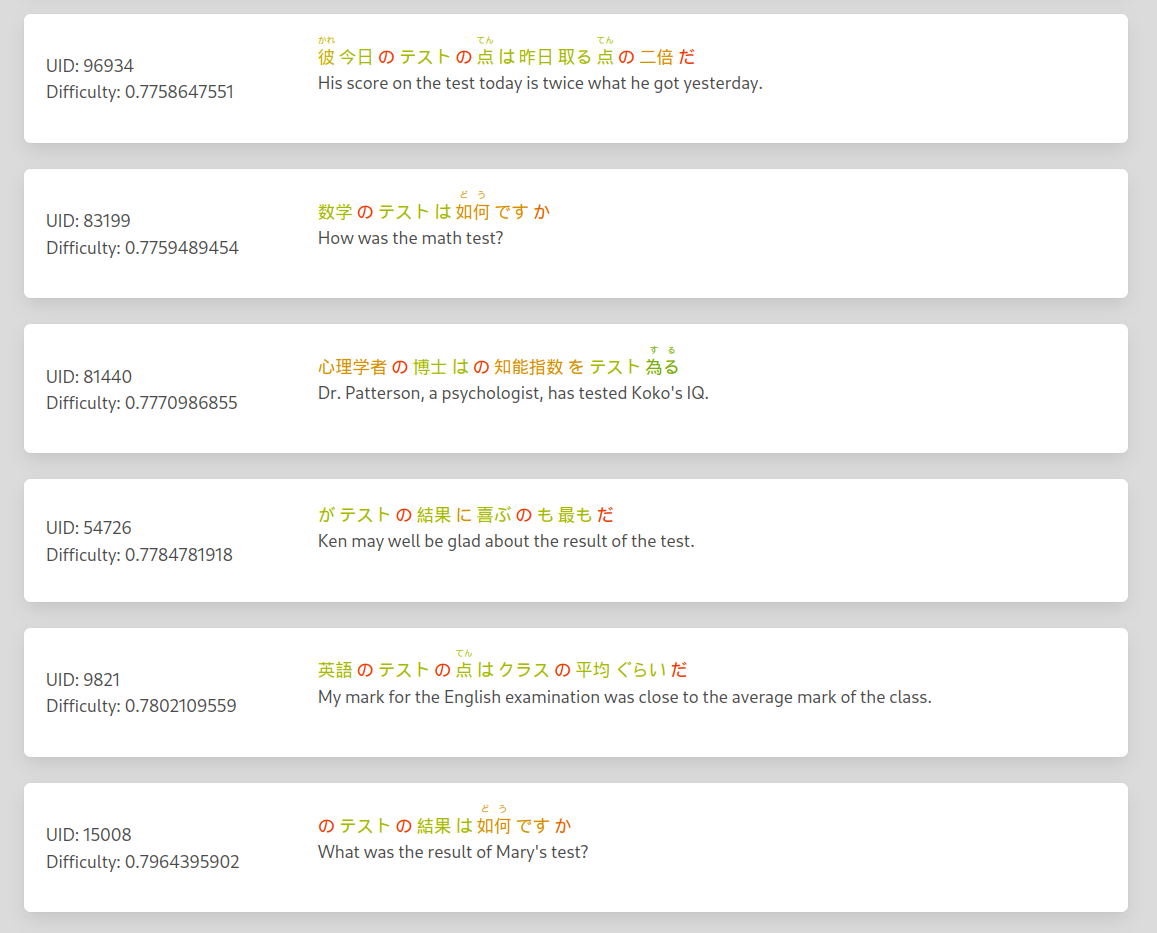
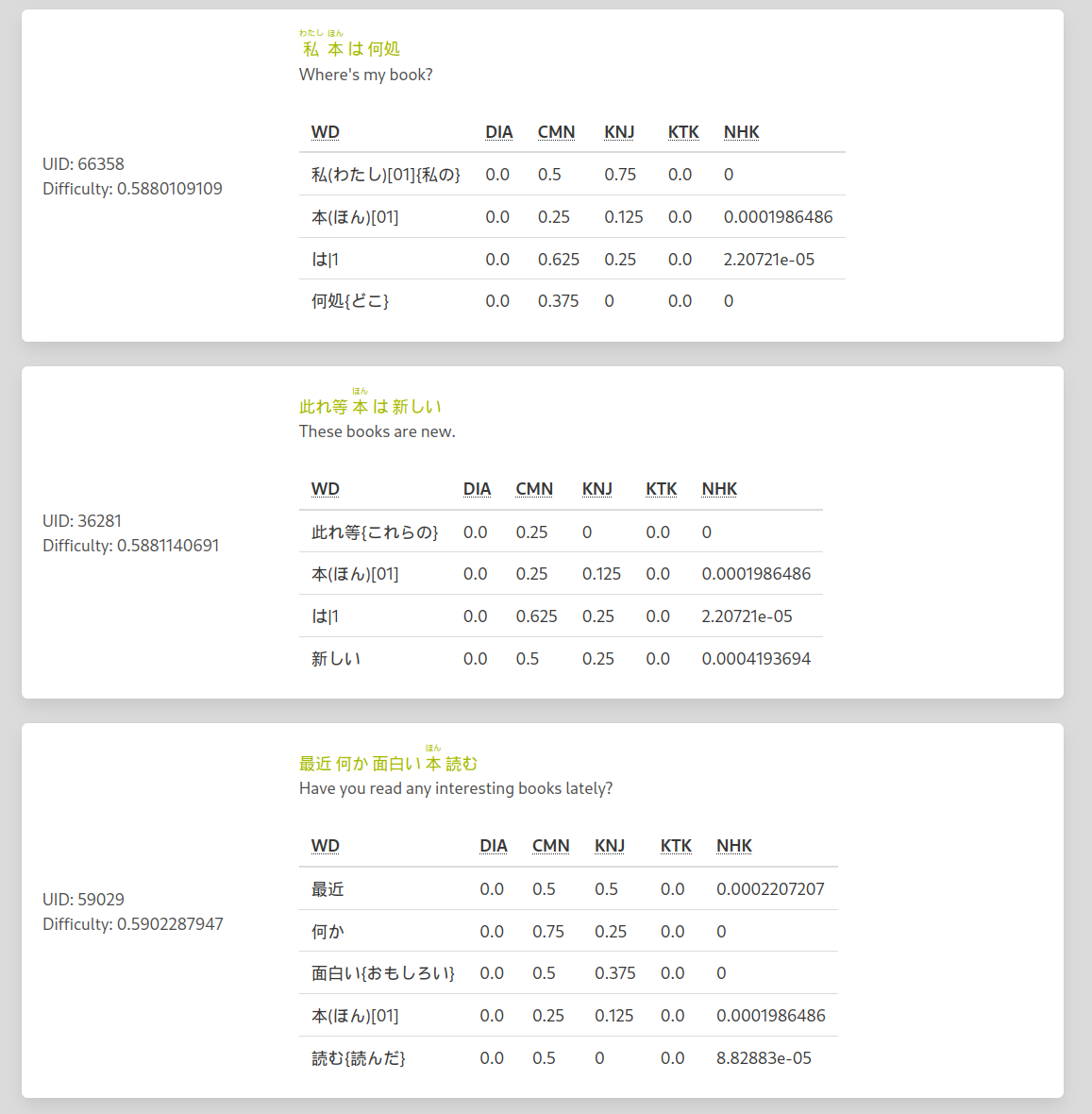
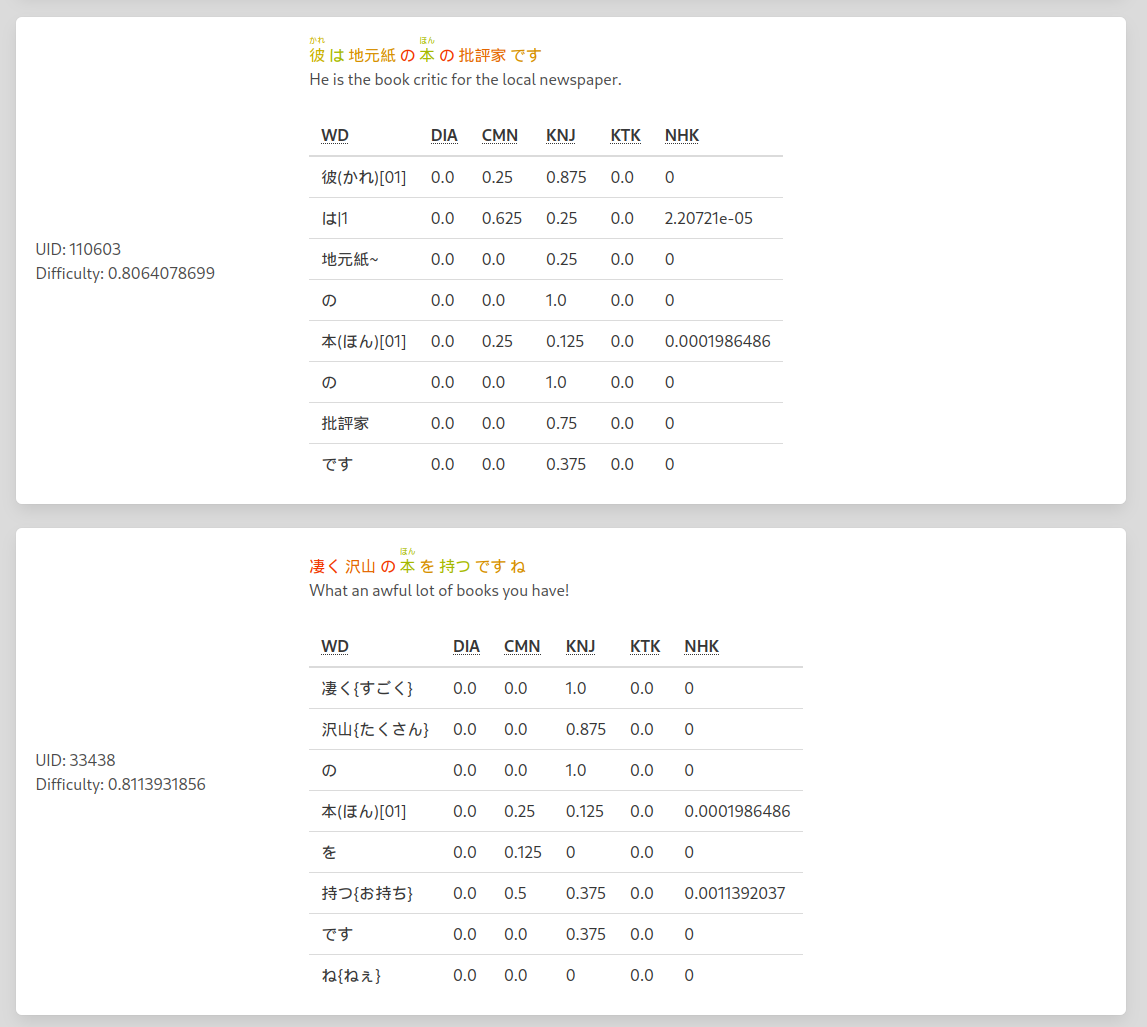
- Apart from some bugs, the system seems to be working as intended
- The factors should be more strongly grounded in linguistical research
- Alternatively a dataset that would make it possible to evaluate the accuracy of the implementation
- More data left unused.