 |
|  |
|  | |
| |
 | | | |
| | | |
 |
|  |
|  |
|
10 ページ の 5 行目 をみなさい
Let's start from (the) fifth line on page 10
##### Multiple readings per kanji 形 - katachi, kata, gyou, kei信用█為る(する){して}█と█彼(かれ)[01]█は|1█言う{言った}
 |
|  |
|  |
|  |
|  |
----
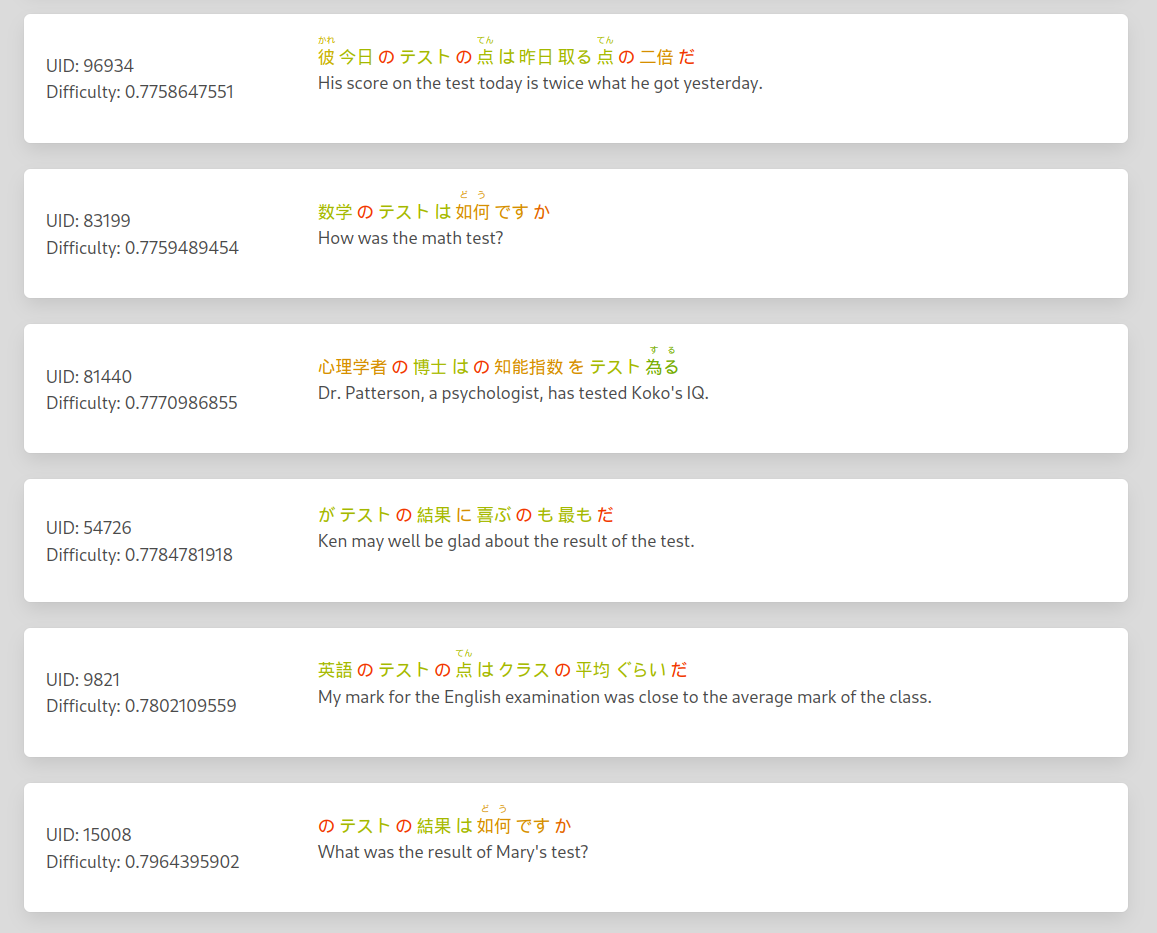
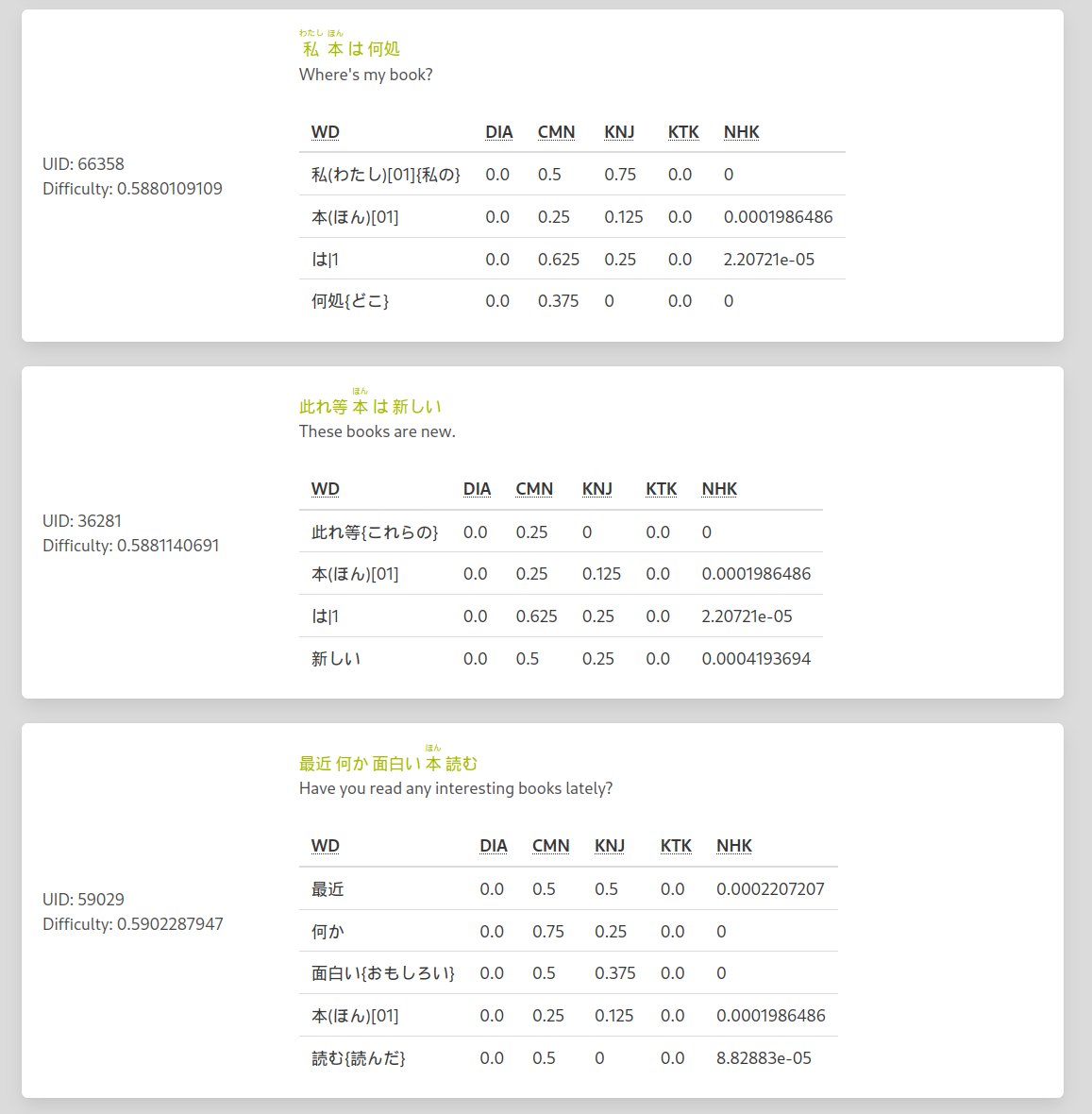
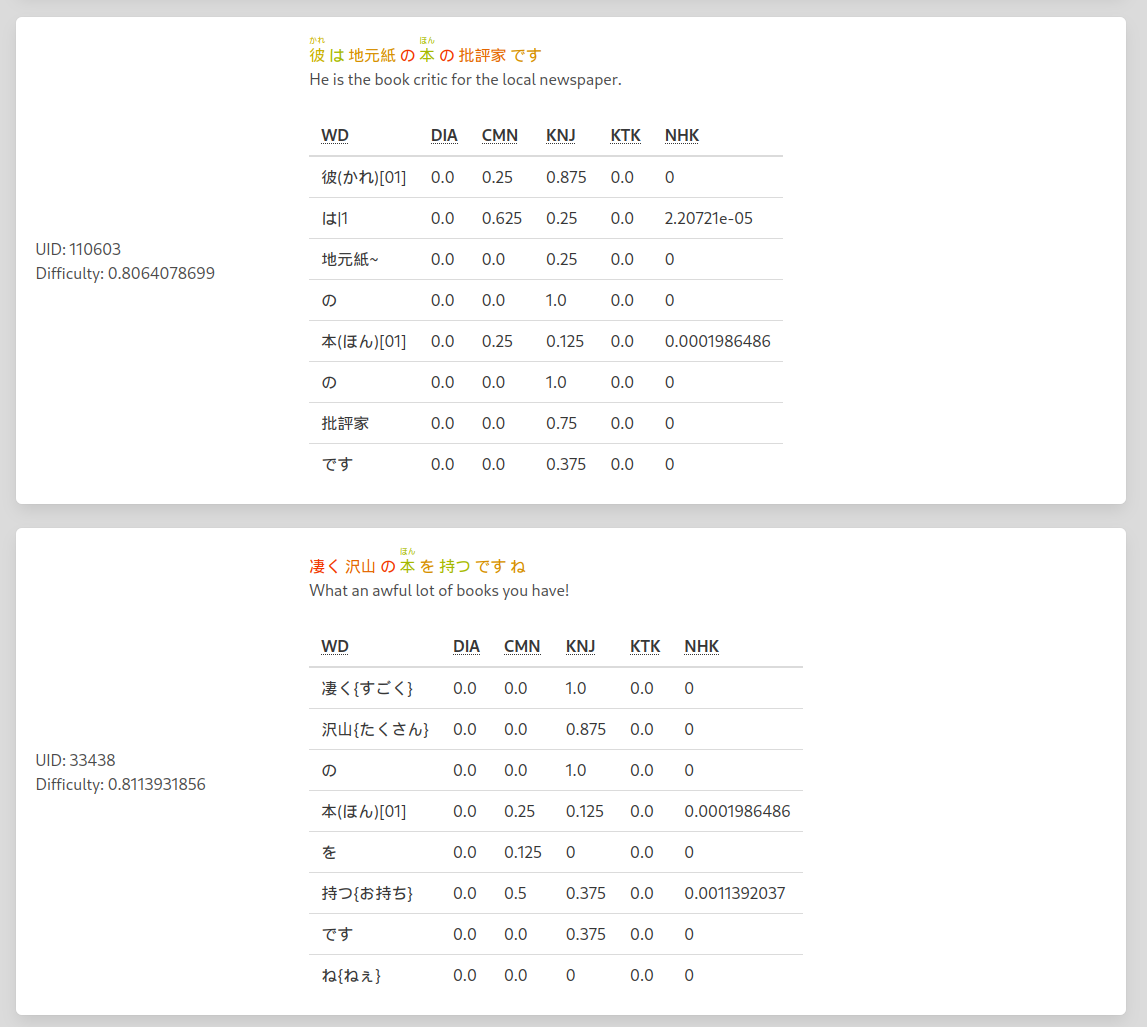
#### Sentence difficulty
| Word difficulty sum | Hardest word | Sentence Length |
|------------|----------|-------|
| 50% | 20 % | 30% |
|
|
----
#### Sentence difficulty
| Word difficulty sum | Hardest word | Sentence Length |
|------------|----------|-------|
| 50% | 20 % | 30% |
|  | |
| |  |
---
|
---